Generate Stunning Images with Stable Diffusion XL on the NVIDIA AI Inference Platform
 Four images of products against enhanced backgrounds.
Four images of products against enhanced backgrounds.
Diffusion models are transforming creative workflows across industries. These models generate stunning images based on simple text or image inputs by iteratively shaping random noise into AI-generated art through denoising diffusion techniques. This can be applied to many enterprise use cases such as creating personalized content for marketing, generating imaginative backgrounds for objects in photos, designing dynamic high-quality environments and characters for gaming, and much more.
While diffusion models can be useful tools to enhance workflows, the models can be extremely computationally intensive when deployed at scale. Generating a single batch of four images can take minutes on non-specialized hardware like CPUs, which can block creative flows and be a barrier for many developers looking to meet strict service level agreements (SLAs).
In this post, we show you how the NVIDIA AI Inference Platform can solve these challenges with a focus on Stable Diffusion XL (SDXL). We start with the common challenges that enterprises face when deploying SDXL in production and dive deeper into how Google Cloud’s G2 instances powered by NVIDIA L4 Tensor Core GPUs, NVIDIA TensorRT, and NVIDIA Triton Inference Server can help mitigate those challenges. We shed light on how Let’s Enhance, a leading AI computer vision startup, is using SDXL on the NVIDIA AI Inference Platform and Google Cloud to enable enterprises to create captivating product images with a single click. Finally, we provide a step-by-step tutorial on how to get started with cost-effective image generation using SDXL on Google Cloud.
Overcoming SDXL production deployment challenges
Deploying any AI workload in production comes with a set of challenges. These include deploying the model within the existing model-serving infrastructure, improving throughput and latency by optimizing batching of inference requests, and keeping infrastructure costs in line with budget constraints.
However, the challenges of deploying diffusion models in production stand out due to their reliance on convolutional neural networks, requirements for image pre– and post-processing operations, and stringent enterprise SLA requirements.
In this post, we delve deeper into each of these aspects and explore how the NVIDIA full stack inference platform can help mitigate them.
Leveraging GPU-specialized Tensor Cores
At the heart of Stable Diffusion lies the U-Net model, which starts with a noisy image—a set of matrices of random numbers. These matrices are chopped into smaller sub-matrices, upon which a sequence of convolutions (mathematical operations) are applied, yielding a refined, less noisy output. Each convolution entails a multiplication and accumulation operation. This denoising process iterates several times until a new, enhanced final image is achieved.

Multiple images show the gradual sharpening of focus objects.
Figure 1. Stable Diffusion denoising process
Given its computational complexity, this procedure significantly benefits from a specific type of GPU core, such as NVIDIA Tensor Cores. These specialized cores were built from the ground up to accelerate matrix multiply-accumulate operations, resulting in faster image generation.
The NVIDIA universal L4 GPU boasts over 200 Tensor Cores and is an ideal cost-effective AI accelerator for enterprises looking to deploy SDXL in production environments. Enterprises can access L4 GPUs through cloud service providers like Google Cloud, the first CSP to offer L4 GPUs in the cloud through its G2 instances.

Picture of the L4 GPU on a black background.
Figure 2. NVIDIA L4 Tensor Core GPU
Automation of image pre– and post-processing
In practical enterprise applications using SDXL, the model is part of a broader AI pipeline that includes other computer vision models and pre– and post-processing image editing steps.
For instance, creating a background scene for a new product launch campaign using SDXL might necessitate a preliminary zoom-in preprocessing step before inputting the product image into the SDXL model for scene generation. The resulting SDXL image output might also need further post-processing, such as upscaling to higher resolutions using an image upscaler before it is suitable for use in a marketing campaign.
Stitching together these various pre– and post-processing steps into a streamlined AI pipeline can be automated using a fully featured AI inference model server, like the open-source Triton Inference Server. This eliminates the need to write manual code or to copy data back and forth across the computing environment, which introduces unnecessary latency and wastes costly compute and networking resources.
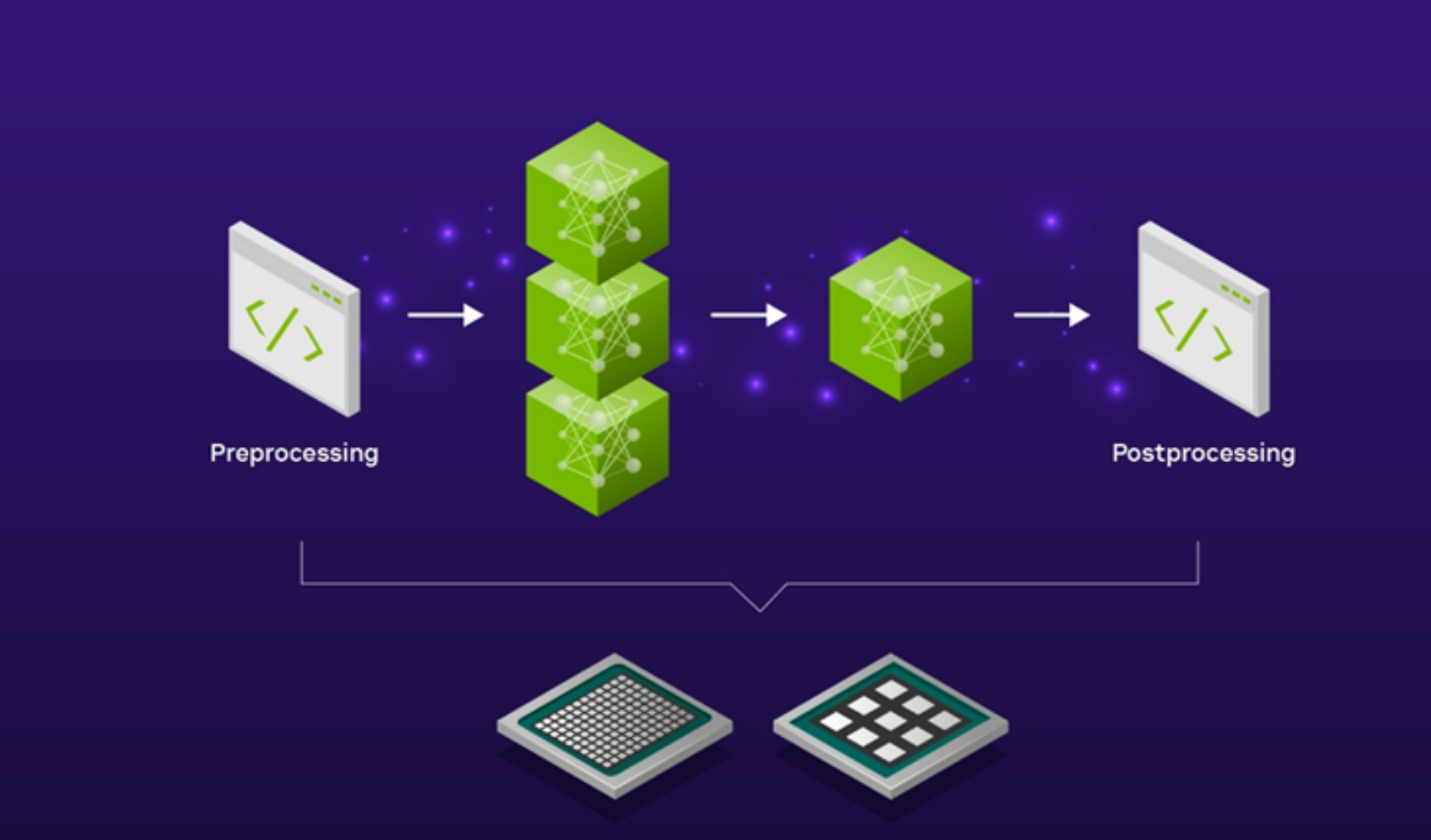
Diagram shows a pipeline that begins with preprocessing and ends with post-processing.
Figure 3. SDXL as part of a broader pipeline
By using Triton Inference Server to serve SDXL models, you can take advantage of the Model Ensembles feature that enables you to define how the output of one model is fed as an input to the next with a low code approach. You can choose to run the pre– and post-processing steps on CPUs and the SDXL model on GPUs or choose to run the entire pipeline on GPUs for ultra-low latency applications. Either option gives you full flexibility and control over the end-to-end latency of your SDXL pipeline.
Efficient scaling for production environments
As more enterprises aim to incorporate SDXL across their lines of business, the challenge of efficiently batching incoming user requests and maximizing GPU utilization becomes increasingly complex. This complexity arises from the need to minimize latency for a positive user experience while simultaneously enhancing throughput to lower operational costs.
The use of an open-source GPU model optimizer like TensorRT, coupled with an inference server with concurrent model execution and dynamic batching capabilities like Triton Inference Server, can alleviate these challenges.
Consider, for instance, the scenario of running an SDXL model in parallel with other TensorFlow and PyTorch image classification or feature extraction AI models, particularly in a production environment with a high volume of incoming client requests. Here, the SDXL model can be compiled with TensorRT, which optimizes the model for low-latency inference.
Triton Inference Server can also efficiently batch and distribute the high volume of incoming requests across the models, regardless of their backend frameworks, through its dynamic batching and concurrent inferencing capability. This approach optimizes throughput, enabling enterprises to meet user requirements with fewer resources and lower total cost of ownership.
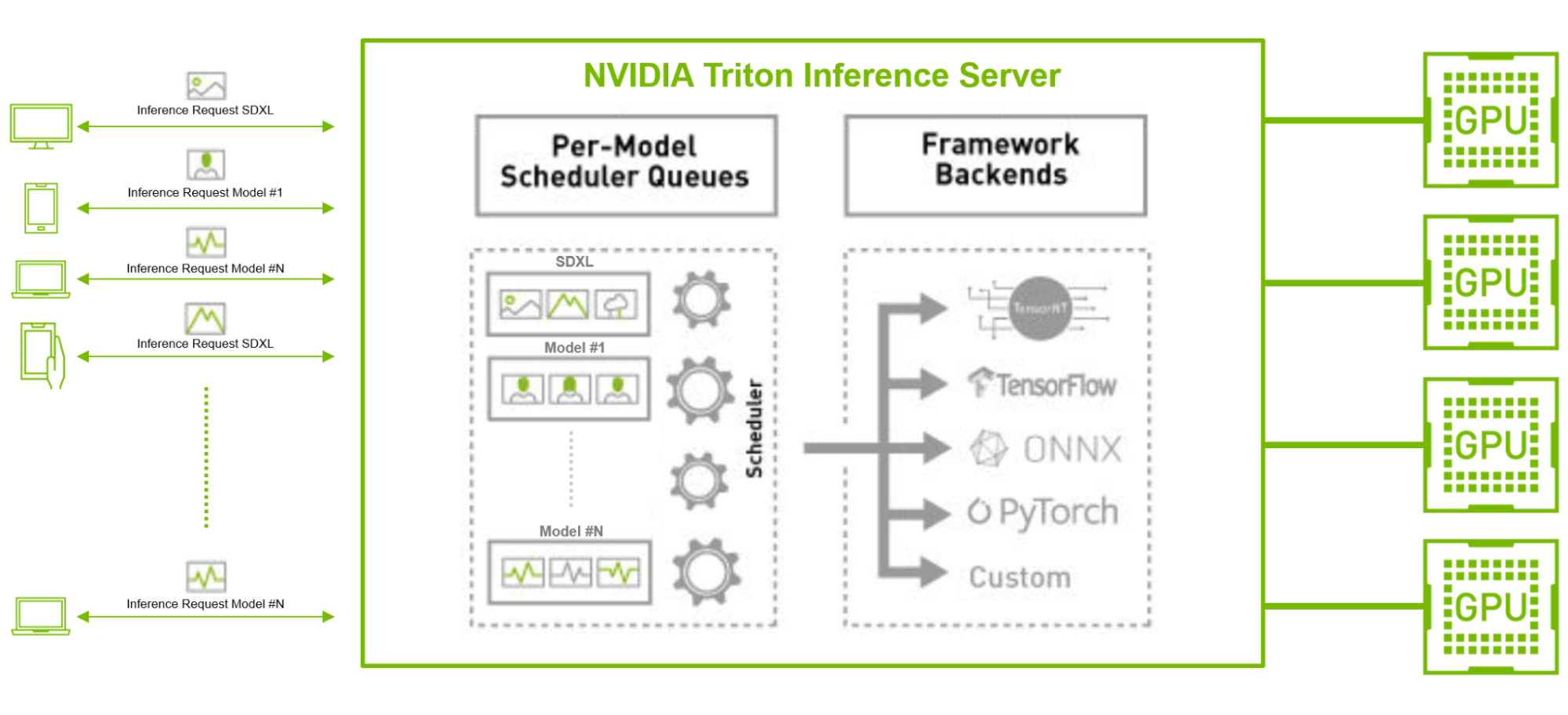
triton-inference-server-multiple-ai-
Diagram shows NVIDIA Triton Inference Server per-model scheduling queues and Stable Diffusion XL served alongside other ML models with different backend frameworks.
Figure 4. NVIDIA Triton serving multiple AI models in a high-volume production environment
Turning plain product photos into beautiful marketing assets
A good example of a company harnessing the power of the NVIDIA AI Inference Platform to serve SDXL in production environments is Let’s Enhance. This pioneering AI startup has been using Triton Inference Server to deploy over 30 AI models on NVIDIA Tensor Core GPUs for over 3 years.
Recently, Let’s Enhance celebrated the launch of their latest product, AI Photoshoot, which uses the SDXL model to transform plain product photos into beautiful visual assets for e-commerce websites and marketing campaigns.
With Triton Inference Server’s robust support for various frameworks and backends, coupled with its dynamic batching feature set, Vlad Pranskevichus, Let’s Enhance Founder and CTO, was able to seamlessly integrate the SDXL model into existing AI pipelines with minimal involvement from the ML Engineering teams, freeing up their time for research and development efforts.
Through a successful proof of concept, the AI image enhancement startup identified a 30% reduction in costs by migrating their SDXL models to NVIDIA L4 GPUs on Google Cloud G2 instances and has outlined a roadmap to complete the migration of several pipelines by mid-2024.

lets-enhance-product-examples
Compilation of four product mockups showcasing a cap bottle, pump bottle, jar, and chair. Each product mockup has two images: one with the object, and one with the object in front of an AI-generated background generated by Let’s Enhance.
Figure 5. Product images generated using Let’s Enhance new PhotoShoot service
Getting started with SDXL using L4 GPUs and TensorRT
In this next section, we demonstrate how you can quickly deploy a TensorRT-optimized version of SDXL on Google Cloud’s G2 instances for the best price performance. To spin up a VM instance on Google Cloud with NVIDIA drivers, follow these steps.
Choose the following machine configuration options:
Machine type: g2-standard-8
CPU platform: Intel Cascade Lake
Minimum CPU platform: None
Display device: Disabled
GPUs: 1 x NVIDIA L4
The g2-standard-8 machine type features one NVIDIA L4 GPU and four vCPUs. Larger machine types are available depending on how much memory is required.
Choose the following boot disk options, making sure that the source image is selected:
Type: Balanced persistent disk
Size: 500 GB
Zone: us-central1-a
Labels: None
In use by: instance-1
Snapshot schedule: None
Source image: c0-deeplearning-common-gpu
Encryption type: Google-managed
Consistency group: None
The Google Deep Learning VM includes the latest NVIDIA GPU libraries.
For the whole article, please check:
Generate Stunning Images with Stable Diffusion XL on the NVIDIA AI Inference Platform
By Amr Elmeleegy, Anjali Shah, Neelay Shah and Rohil Bhargava/NVDIA

熱門頭條新聞
- How will multimodal AI change the world?
- Moana 2
- AI in the Workplace
- Challenging Amazon: Walmart’s Vision for the Future of Subscription Streaming
- LAUNCH OF AN UNPRECEDENTED ALLIANCE BETWEEN EUROPEAN FILM AND AUDIOVISUAL MARKETS
- Marvel Rivals Unveils Launch Trailer
- The Studio Park Thailand: A Pemier Production Hub for Southeast Asia
- ABC Commercial partners with Amagi to launch suite of FAST channels
