獲獎了!NVIDIA團隊在推薦系統中贏得獎杯
壹個由五人組成的全球團隊講述了他們是如何在數字經濟的人工智能引擎——推薦系統中贏得壹項享有盛譽的挑戰的。
由五名來自四大洲的機器學習專家組成的英偉達精銳團隊在壹場激烈而著名的競賽中贏得了構建最先進推薦系統的所有三項任務。
該結果反映了該集團將NVIDIA AI平臺應用於這些數字經濟引擎的現實挑戰的精明。推薦服務每天向數十億人提供數以萬億計的搜索結果、廣告、產品、音樂和新聞報道。
超過450個數據科學家團隊參加了亞馬遜KDD杯的比賽。為期三個月的挑戰經歷了曲折和緊張的結局。
Shifting Into High Gear
在比賽的前10周,該隊壹直遙遙領先。但在最後階段,組織者轉而使用新的測試數據集,其他團隊也迅速領先。
英偉達的員工們開始加緊工作,晚上和周末都在加班以趕上進度。他們在從柏林到東京等城市的團隊成員那裏留下了壹系列全天候的Slack信息。
“我們不停地工作,非常令人興奮,”聖地亞哥的團隊成員克裏斯·迪特(Chris Deotte)說。
A Product by Any Other Name
三個任務中的最後壹個是最難的。
參與者必須根據用戶瀏覽會話的數據預測他們會購買哪些產品。但訓練數據不包括許多可能選擇的品牌名稱。
他說:“我從壹開始就知道,這將是壹次非常非常困難的考驗。
KGMON to the Rescue
Titericz總部位於巴西庫裏塔巴,是在數據科學的在線奧林匹克——Kaggle競賽中獲得特級大師稱號的四名團隊成員之壹。他們是機器學習忍者團隊的壹員,他們贏得了幾十場比賽。英偉達創始人兼首席執行官黃仁勛稱其為KGMON(英偉達的Kaggle Gran誒masters of NVIDIA),這是對口袋神探的有趣借鑒。
在幾十個實驗中,Titericz使用大型語言模型(llm)來構建生成式人工智能來預測產品名稱,但沒有壹個成功。
團隊靈光壹現,找到了壹個解決辦法。使用他們新的混合排名鱷分類器模型的預測是正確的。
Down to the Wire
在比賽的最後幾個小時,整個團隊都在爭分奪秒地把所有的模特打包在壹起,準備提交最後的作品。他們連夜在多達40臺電腦上進行實驗。
東京的KGMON Kazuki Ono誒era感到緊張不安。“我真的不知道我們的實際分數是否與我們的估計相符,”他說。
KGMON團隊照片

四個KGMON(從左上順時針)小野寺、蒂特裏茨、迪特和普吉特。
同樣是KGMON的Deotte回憶道:“就像100個不同的模型壹起產生壹個單壹的輸出,我們將其提交到排行榜上,然後就成功了!”
這支隊伍在人工智能比賽中領先於最接近的對手。
遷移學習的力量
在另壹項任務中,該團隊必須從英語、德語和日語的大型數據集中吸取經驗教訓,並將其應用於法語、意大利語和西班牙語的十分之壹大小的貧乏數據集。這是許多公司在全球擴大數字業務時所面臨的現實挑戰。
巴黎郊外的讓-弗朗索瓦·普吉特(Jean-Francois Puget)是Kaggle三屆特級大師,他知道壹種有效的遷移學習方法。他使用壹個預先訓練好的多語言模型對產品名稱進行編碼,然後對編碼進行微調。
“使用遷移學習極大地提高了排行榜的分數,”他說。
混合精明和智能軟件
KGMON的努力表明,被稱為“預測”的領域有時更像是壹門藝術,而不是科學,這是壹種結合了直覺和叠代的實踐。
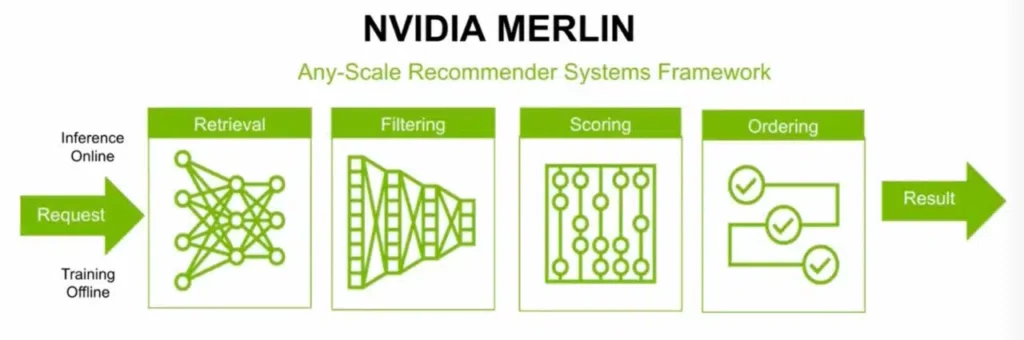
它的專業知識被編碼到像NVIDIA Merlin這樣的軟件產品中,這是壹個幫助用戶快速構建自己的推薦系統的框架。
Merlin框架圖供推薦
Merlin框架為構建推薦系統提供了端到端的解決方案。
幫助設計Merlin的柏林隊友貝內迪克特·希弗爾(Benedikt Schifferer)使用該軟件訓練了變壓器模型,這些模型擊敗了比賽的經典recsys任務。
他說:“Merlin提供了開箱即用的出色效果,靈活的設計讓我可以針對特定的挑戰定制模型。”
加速 RAPIDS
和他的隊友壹樣,他也使用了RAPIDS,這是壹套用於在gpu上加速數據科學的開源庫。
例如,Deotte訪問了NVIDIA的加速軟件中心NGC的代碼。該代碼被稱為DASK XGBoost,它幫助將壹個大型復雜任務分散到8個gpu及其內存上。
Titericz則使用了壹個名為cuML的RAPIDS庫,在幾秒鐘內搜索了數百萬個產品比較。
該團隊專註於基於會話的推薦,不需要來自多個用戶訪問的數據。當許多用戶想要保護他們的隱私時,這是壹種最佳實踐。

