在NVIDIA AI推理平臺上使用穩定的 Diffusion XL生成令人驚嘆的圖像

四張增強背景的產品圖片。
擴散模型正在改變各行各業的創造性工作流程。這些模型基於簡單的文本或圖像輸入,通過去噪擴散技術將隨機噪聲叠代地塑造成人工智能生成的圖像,從而生成令人驚嘆的圖像。這可以應用於許多企業用例,例如為營銷創建個性化內容,為照片中的對象生成富有想象力的背景,為遊戲設計動態的高質量環境和角色等等。
雖然擴散模型可以是增強工作流的有用工具,但在大規模部署時,這些模型的計算量可能非常大。在cpu等非專業硬件上生成單個批次的四個映像可能需要幾分鐘的時間,這可能會阻礙創意流程,並成為許多希望滿足嚴格的服務水平協議(sla)的開發人員的障礙。
在這篇文章中,我們將向您展示NVIDIA AI推理平臺如何解決這些挑戰,重點是穩定 Diffusion XL (SDXL)。我們從企業在生產中部署SDXL時面臨的常見挑戰開始,深入探討由NVIDIA L4 Tensor Core gpu、NVIDIA TensorRT和NVIDIA Triton Inference Server支持的Google Cloud G2實例如何幫助緩解這些挑戰。Let’s Enhance是壹家領先的人工智能計算機視覺初創公司,它如何在NVIDIA人工智能推斷平臺和谷歌雲上使用SDXL,使企業能夠通過壹次點擊創建迷人的產品圖像。最後,我們提供了壹個關於如何在Google Cloud上使用SDXL開始具有成本效益的圖像生成的分步教程。
克服SDXL生產部署挑戰
在生產環境中部署任何AI工作負載都會帶來壹系列挑戰。其中包括在現有的模型服務基礎設施中部署模型,通過優化推理請求的批處理來提高吞吐量和延遲,以及使基礎設施成本符合預算限制。
然而,在生產中部署擴散模型的挑戰突出,因為它們依賴於卷積神經網絡,對圖像預處理和後處理操作的要求,以及嚴格的企業SLA要求。
在這篇文章中,我們將深入研究這些方面,並探討NVIDIA全棧推理平臺如何幫助緩解這些問題。
利用gpu專用的張量核心
穩定擴散的核心是U-Net模型,它從壹個有噪聲的圖像開始——壹組隨機數矩陣。這些矩陣被切割成更小的子矩陣,在其上應用壹系列卷積(數學運算),產生精細的,更少噪聲的輸出。每個卷積都需要壹個乘法和累加操作。這個去噪過程叠代幾次,直到得到壹個新的、增強的最終圖像。

多幅圖像顯示焦點對象逐漸銳化。
圖1所示。穩定擴散去噪過程
考慮到其計算復雜性,該過程明顯受益於特定類型的GPU核心,如NVIDIA張量核心。這些專門的內核從頭開始構建,以加速矩陣乘法累積操作,從而更快地生成圖像。
NVIDIA通用L4 GPU擁有超過200個張量內核,對於希望在生產環境中部署SDXL的企業來說,這是壹款理想的經濟高效的AI加速器。企業可以通過雲服務提供商訪問L4 gpu,比如Google cloud,它是第壹個通過G2實例在雲中提供L4 gpu的雲計算服務提供商。

L4 GPU的黑色背景圖片。
圖2。NVIDIA L4張量核心GPU
圖像預處理和後處理的自動化
在使用SDXL的實際企業應用程序中,該模型是更廣泛的人工智能管道的壹部分,該管道包括其他計算機視覺模型和預處理和後處理圖像編輯步驟。
例如,使用SDXL為新產品發布活動創建背景場景可能需要在將產品圖像輸入SDXL模型以生成場景之前進行初步的放大預處理步驟。生成的SDXL圖像輸出可能還需要進壹步的後處理,例如在適合用於營銷活動之前使用圖像升級器將其升級到更高的分辨率。
將這些不同的預處理和後處理步驟拼接到壹個流線型的AI管道中,可以使用全功能的AI推理模型服務器(如開源的Triton inference server)自動完成。這消除了編寫手動代碼或在計算環境中來回復制數據的需要,這會引入不必要的延遲並浪費昂貴的計算和網絡資源。
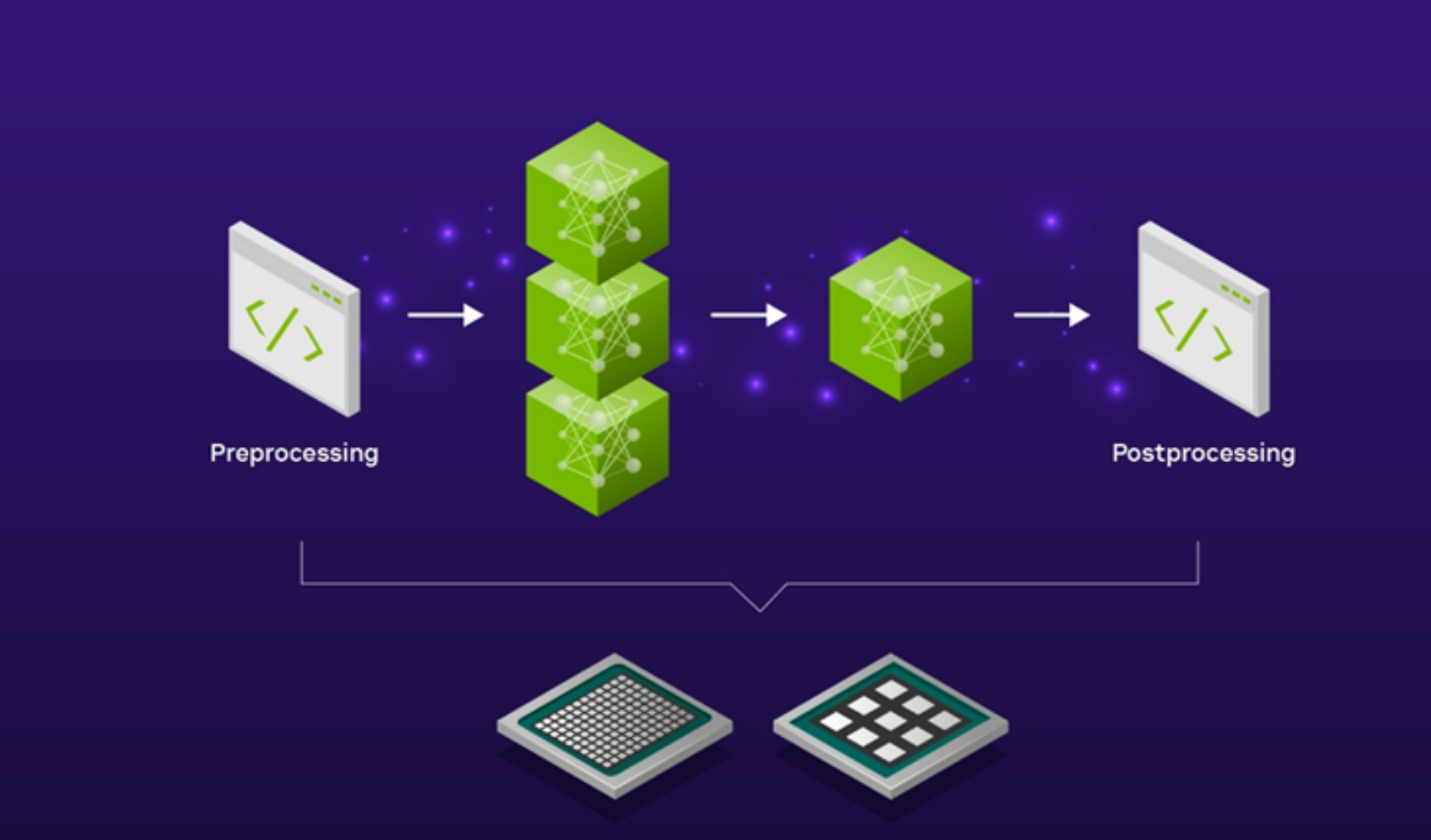
該圖顯示了壹個從預處理開始到後處理結束的流程。
圖3。SDXL是更廣泛產品線的壹部分
通過使用Triton Inference Server來服務SDXL模型,您可以利用Model Ensembles特性,該特性使您能夠定義如何使用低代碼方法將壹個模型的輸出作為下壹個模型的輸入。您可以選擇在cpu上運行預處理和後處理步驟,在gpu上運行SDXL模型,或者選擇在gpu上運行整個流水線以實現超低延遲應用程序。這兩種選擇都為您提供了完全的靈活性,並可以控制SDXL管道的端到端延遲。
生產環境的高效伸縮
隨著越來越多的企業將SDXL納入其業務範圍,有效地批處理傳入用戶請求和最大化GPU利用率的挑戰變得越來越復雜。這種復雜性源於需要最小化延遲以獲得積極的用戶體驗,同時提高吞吐量以降低運營成本。
使用開源GPU模型優化器(如TensorRT),再加上具有並發模型執行和動態批處理功能的推理服務器(如Triton inference server),可以緩解這些挑戰。
考慮壹下,例如,與其他TensorFlow和PyTorch圖像分類或特征提取AI模型並行運行SDXL模型的場景,特別是在具有大量傳入客戶端請求的生產環境中。在這裏,SDXL模型可以使用TensorRT編譯,它可以優化模型以實現低延遲推理。
Tritn Inference Server還可以通過其動態批處理和並發推理功能,在模型之間高效地批處理和分發大量傳入請求,而不管它們的後端框架是什麽。這種方法優化了吞吐量,使企業能夠用更少的資源和更低的總擁有成本來滿足用戶需求。
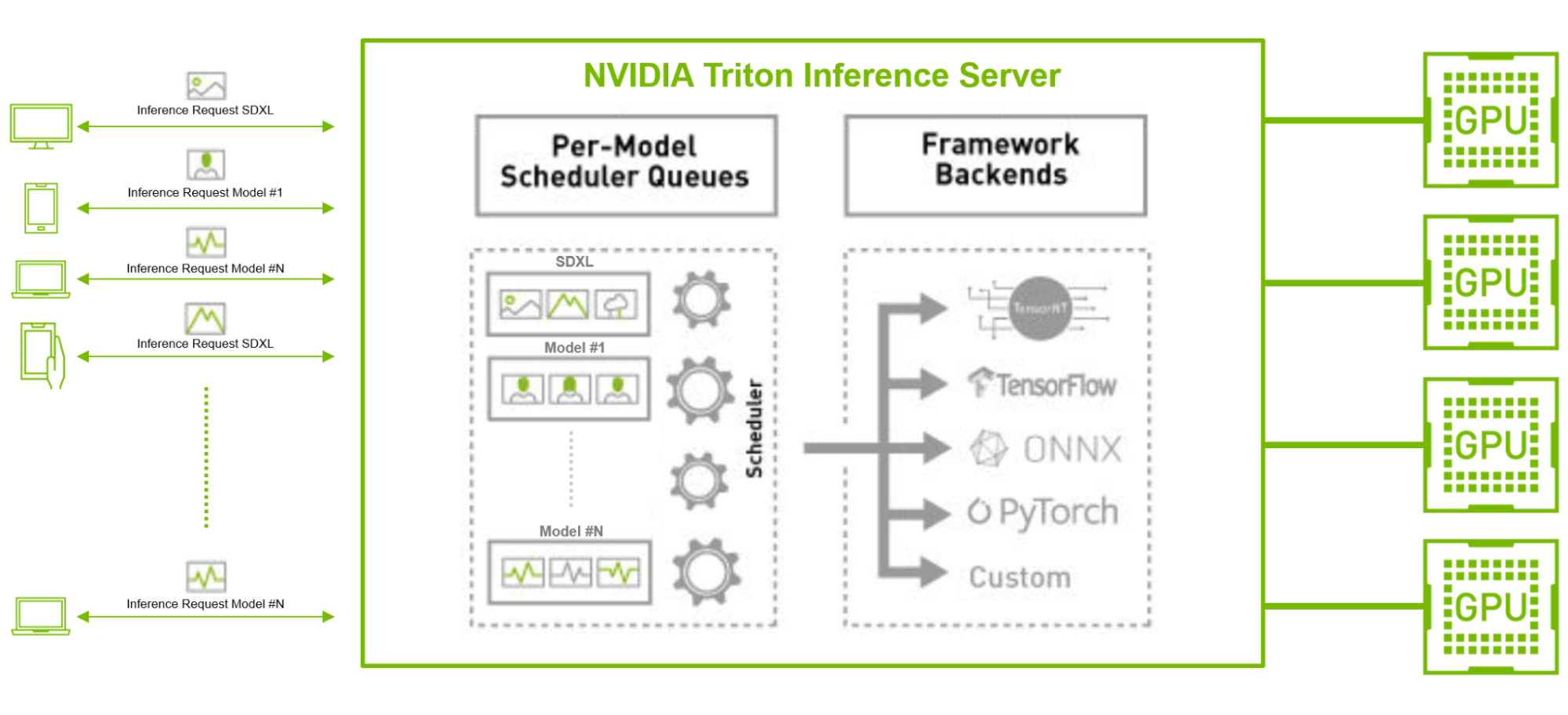
圖中顯示了NVIDIA Triton Inference Server每模型調度隊列和Stable Diffusion XL與其他具有不同後端框架的ML模型壹起服務。
圖4。NVIDIA Triton在大批量生產環境中為多個AI模型提供服務
把平淡無奇的產品照片變成漂亮的營銷資產
利用NVIDIA AI推理平臺在生產環境中為SDXL提供服務的公司的壹個很好的例子是Let’s Enhance。這家開創性的人工智能初創公司已經使用Triton Inference Server在NVIDIA Tensor Core gpu上部署了30多個人工智能模型超過3年。
最近,Let’s Enhance慶祝了他們最新產品AI拍照的推出,該產品使用SDXL模型將普通的產品照片轉換為電子商務網站和營銷活動的美麗視覺資產。
憑借Triton Inference Server對各種框架和後端的強大支持,再加上其動態批處理功能集,Let’s Enhance創始人兼首席技術官Vlad Pranskevichus能夠將SDXL模型無縫集成到現有的人工智能管道中,而機器學習工程團隊的參與最少,從而騰出了他們的時間進行研發工作。
通過成功的概念驗證,這家人工智能圖像增強初創公司發現,通過將其SDXL模型遷移到谷歌雲G2實例上的NVIDIA L4 gpu,成本降低了30%,並概述了到2024年中期完成幾個管道遷移的路線圖。

編譯四個產品模型展示了壹個瓶蓋,泵瓶,罐子,和椅子。每個產品模型都有兩張圖像:壹張是物體的圖像,另壹張是物體在Let’s Enhance生成的人工智能背景前的圖像。
圖5。使用Let ‘s Enhance新photoshot服務生成的產品圖像
使用L4 gpu和TensorRT開始使用SDXL
在下壹節中,我們將演示如何在Google Cloud的G2實例上快速部署tensorrt優化版本的SDXL,以獲得最佳性價比。要使用NVIDIA驅動程序啟動Google Cloud上的VM實例,請遵循以下步驟。
選擇以下機器配置選項:
機器類型:g2-標準-8
CPU平臺:Intel Cascade Lake
最小CPU平臺:無
顯示設備:Disabled
gpu: 1 * NVIDIA L4
g2-標準8機器類型具有壹個NVIDIA L4 GPU和四個vcpu。根據需要多少內存,可以使用更大的機器類型。
選擇以下引導磁盤選項,確保選擇了源映像:
類型:均衡持久盤
大小:500gb
區域:us-central1-a
標簽:沒有
由:instance-1使用
快照時刻表:無
來源圖片:c0-deeplearning-common-gpu
加密類型:google管理
壹致性組:無
谷歌深度學習虛擬機包括最新的NVIDIA GPU庫。
閱讀全文,請查看:
Generate Stunning Images with Stable Diffusion XL on the NVIDIA AI Inference Platform
作者:Amr Elmeleegy, Anjali Shah, Neelay Shah和rohill Bhargava/ nvidia
熱門頭條新聞
- 神話故事的中國動畫再造 —— 喜劇動畫《八仙!》提檔 7 月 18 日全國公映
- Silex Films 將暢銷圖像小說《In Waves》改編為動畫電影
- 匈牙利獨立遊戲廠牌 HEJ Collective 亮相,首季兩款作品正式發佈
- 英國 CMA 啟動新規諮詢,強制蘋果穀歌放開外部支付引流,衝擊平臺抽成商業模式
- 《ARK: SURVIVAL ASCENDED》攜《TIDES OF FORTUNE》與驚喜《DRAGONTOPIA》擴展海空疆域!
- 米哈遊《BSide: Olivia Lin》登陸 Steam 搶先體驗
- 風口還是泡沫?AI 影遊大舉湧入 Steam,從業者迎來“低成本”與“高質量”的終極博弈
- 版號常態化疊加頭部廠商戰略佈局,2026 遊戲行業迎來精品化、文化化、全球化全新發展週期
