人工智能醫學圖像模型提供快速,經濟高效的專家分析
加州大學洛杉磯分校的研究人員開髮了一種新的人工智能模型,可以在人類臨床專家所需的一小部分時間內熟練地分析疾病的3D醫學圖像。
這個名爲SLIViT (SLice Integration by Vision Transformer)的深度學習框架分析來自不同圖像模式的圖像,包括視網膜掃描、超聲視頻、ct、核磁共振等,以識別潛在的疾病風險生物標誌物。
領導這項研究的加州大學洛杉磯分校(UCLA)計算醫學專家、教授埃蘭·哈爾佩林博士表示,該模型在多種疾病中都非常準確,優於許多現有的針對特定疾病的基礎模型。它使用了一種新的預訓練和微調方法,這種方法依賴於大型的、可訪問的公共數據集。因此,Halperin相信該模型可以以相對較低的成本用於識別不同的疾病生物標誌物,使專家級醫學成像分析客觀化。
研究人員使用了NVIDIA T4 gpu和NVIDIA V100 Tensor Core gpu,以及NVIDIA CUDA來進行研究。
目前,醫學圖像專家經常不堪重負。在開始治療之前,患者通常要等上幾週才能接受x光、核磁共振或CT掃描評估。
SLIViT的潛在優勢之一是它能夠熟練地大規模分析患者數據,以及如何昇級其專業知識。例如,一旦新的醫學成像技術被開髮出來,模型就可以根據新數據進行微調,這些數據可以被推出並用於未來的分析。
哈爾佩林博士指出,該模型也很容易部署。特別是在缺乏醫學圖像專家的地方,未來該模型可能會對患者的治療結果産生重大影響。
哈爾佩林博士説,在SLIViT出現之前,以人類臨床專家的水平評估大量掃描結果實際上是不可行的。有了SLIViT,大規模、準確的分析是現實的。
“該模型可以在識別疾病生物標誌物方麵産生巨大影響,而不需要大量手動注釋的圖像,”哈爾佩林博士説。“這些疾病生物標誌物可以幫助我們了解患者的疾病軌跡。在未來,有可能利用這些見解來根據通過SLIVIT髮現的生物標誌物爲患者量身定製治療,並有望顯著改善患者的生活。”
加州大學洛杉磯分校研究人員髮表在《自然生物醫學工程》上的一篇論文的主要作者奧倫·阿夫拉姆博士説,這項研究揭示了兩個令人驚訝但又相關的結果。
兩個並排的3D視頻圖像顯示了通過光學相幹斷層掃描成像掃描觀察到的人類視網膜的兩個橫截麵。
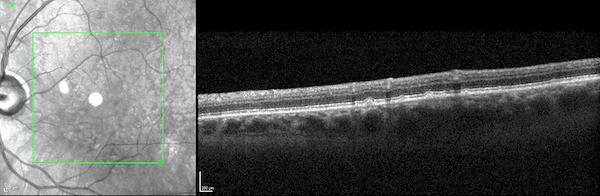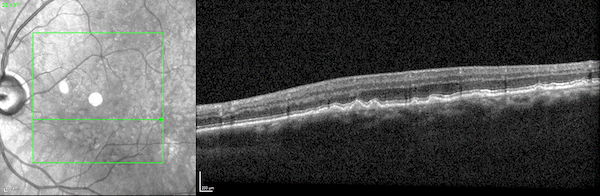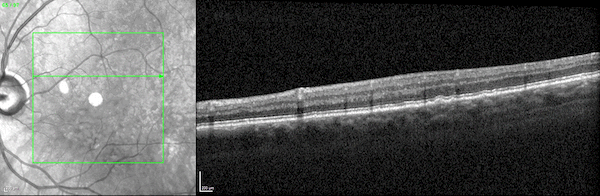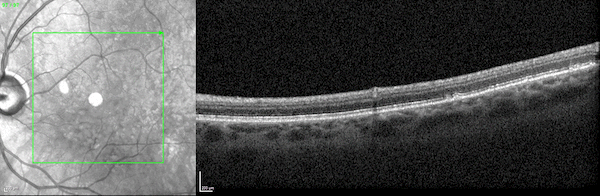
圖1所示。人類視網膜的三維光學相幹斷層掃描
首先,雖然該模型在很大程度上是在2D掃描數據集上進行預訓練的,但它能準確識別人體器官3D掃描中的疾病生物標誌物。通常,設計用於分析3D圖像的模型是在3D數據集上訓練的。但3D醫療數據的獲取成本要高得多,因此遠不如2D醫療數據豐富和可訪問。
加州大學洛杉磯分校的研究人員髮現,通過在2D掃描上預先訓練他們的模型(2D掃描更容易接近),並在相對少量的3D掃描上對其進行微調,該模型的表現優於僅在3D掃描上訓練的專門模型。
第二個意想不到的結果是該模型在遷移學習方麵的表現。它學會了通過微調數據集來識別不同的疾病生物標誌物,這些數據集由來自不同形態和器官的圖像組成。
“我們在二維視網膜掃描上訓練模型,也就是眼睛的圖像,然後在肝髒的核磁共振上對模型進行微調,這看起來沒有聯繫,因爲它們是兩個完全不同的器官和成像技術,”Avram説。“但我們了解到,在視網膜和肝髒之間,以及在OCT和MRI之間,一些基本特徵是共享的,這些特徵可以用來幫助模型進行下遊學習,即使圖像域完全不同。”

