获奖了!NVIDIA团队在推荐系统中赢得奖杯
一个由五人组成的全球团队讲述了他们是如何在数字经济的人工智能引擎——推荐系统中赢得一项享有盛誉的挑战的。
由五名来自四大洲的机器学习专家组成的英伟达精锐团队在一场激烈而著名的竞赛中赢得了构建最先进推荐系统的所有三项任务。
该结果反映了该集团将NVIDIA AI平台应用于这些数字经济引擎的现实挑战的精明。推荐服务每天向数十亿人提供数以万亿计的搜索结果、广告、产品、音乐和新闻报道。
超过450个数据科学家团队参加了亚马逊KDD杯的比赛。为期三个月的挑战经历了曲折和紧张的结局。
Shifting Into High Gear
在比赛的前10周,该队一直遥遥领先。但在最后阶段,组织者转而使用新的测试数据集,其他团队也迅速领先。
英伟达的员工们开始加紧工作,晚上和周末都在加班以赶上进度。他们在从柏林到东京等城市的团队成员那里留下了一系列全天候的Slack信息。
“我们不停地工作,非常令人兴奋,”圣地亚哥的团队成员克里斯·迪特(Chris Deotte)说。
A Product by Any Other Name
三个任务中的最后一个是最难的。
参与者必须根据用户浏览会话的数据预测他们会购买哪些产品。但训练数据不包括许多可能选择的品牌名称。
他说:“我从一开始就知道,这将是一次非常非常困难的考验。
KGMON to the Rescue
Titericz总部位于巴西库里塔巴,是在数据科学的在线奥林匹克——Kaggle竞赛中获得特级大师称号的四名团队成员之一。他们是机器学习忍者团队的一员,他们赢得了几十场比赛。英伟达创始人兼首席执行官黄仁勋称其为KGMON(英伟达的Kaggle Grandmasters of NVIDIA),这是对口袋神探的有趣借鉴。
在几十个实验中,Titericz使用大型语言模型(llm)来构建生成式人工智能来预测产品名称,但没有一个成功。
团队灵光一现,找到了一个解决办法。使用他们新的混合排名/分类器模型的预测是正确的。
Down to the Wire
在比赛的最后几个小时,整个团队都在争分夺秒地把所有的模特打包在一起,准备提交最后的作品。他们连夜在多达40台电脑上进行实验。
东京的KGMON Kazuki Onodera感到紧张不安。“我真的不知道我们的实际分数是否与我们的估计相符,”他说。
KGMON团队照片

四个KGMON(从左上顺时针)小野寺、蒂特里茨、迪特和普吉特。
同样是KGMON的Deotte回忆道:“就像100个不同的模型一起产生一个单一的输出,我们将其提交到排行榜上,然后就成功了!”
这支队伍在人工智能比赛中领先于最接近的对手。
迁移学习的力量
在另一项任务中,该团队必须从英语、德语和日语的大型数据集中吸取经验教训,并将其应用于法语、意大利语和西班牙语的十分之一大小的贫乏数据集。这是许多公司在全球扩大数字业务时所面临的现实挑战。
巴黎郊外的让-弗朗索瓦·普吉特(Jean-Francois Puget)是Kaggle三届特级大师,他知道一种有效的迁移学习方法。他使用一个预先训练好的多语言模型对产品名称进行编码,然后对编码进行微调。
“使用迁移学习极大地提高了排行榜的分数,”他说。
混合精明和智能软件
KGMON的努力表明,被称为“预测”的领域有时更像是一门艺术,而不是科学,这是一种结合了直觉和迭代的实践。
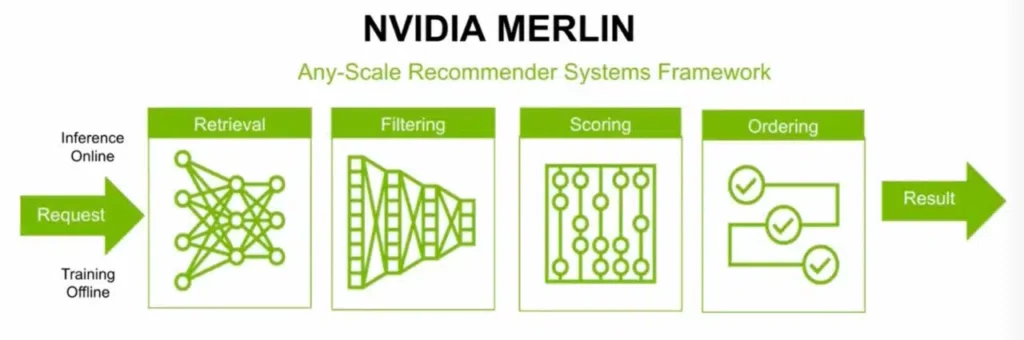
它的专业知识被编码到像NVIDIA Merlin这样的软件产品中,这是一个帮助用户快速构建自己的推荐系统的框架。
Merlin框架图供推荐
Merlin框架为构建推荐系统提供了端到端的解决方案。
帮助设计Merlin的柏林队友贝内迪克特·希弗尔(Benedikt Schifferer)使用该软件训练了变压器模型,这些模型击败了比赛的经典recsys任务。
他说:“Merlin提供了开箱即用的出色效果,灵活的设计让我可以针对特定的挑战定制模型。”
加速 RAPIDS
和他的队友一样,他也使用了RAPIDS,这是一套用于在gpu上加速数据科学的开源库。
例如,Deotte访问了NVIDIA的加速软件中心NGC的代码。该代码被称为DASK XGBoost,它帮助将一个大型复杂任务分散到8个gpu及其内存上。
Titericz则使用了一个名为cuML的RAPIDS库,在几秒钟内搜索了数百万个产品比较。
该团队专注于基于会话的推荐,不需要来自多个用户访问的数据。当许多用户想要保护他们的隐私时,这是一种最佳实践。

